
The Core Idea
Your two eyes judge depth because they see the same scene from slightly different positions; your brain fuses that parallax into 3D. Photogrammetry does the same thing with a camera. Photograph a subject from many positions, and any point that appears in several images can be triangulated: where the lines of sight from each camera cross is its position in 3D space.
The breakthrough is that the software does not need to be told where the cameras were. It figures out the camera positions and the 3D scene at the same time, purely from the photos — the technique called Structure-from-Motion.
Structure-from-Motion (SfM)
SfM is the engine inside modern photogrammetry. The pipeline runs roughly like this:
- Feature detection — the software finds thousands of distinctive points (corners, textures) in each photo.
- Matching — it identifies the same features appearing across multiple images.
- Bundle adjustment — it solves for every camera’s position and orientation, plus a sparse cloud of those tie points, all at once, minimizing the total reprojection error.
- Dense reconstruction — with the cameras known, it computes depth for far more pixels, producing a dense point cloud.
- Meshing & texturing — the cloud is turned into a surface and the original photos are draped over it as a photorealistic texture.
Overlap Is Everything
A feature has to appear in several photos to be reconstructed, so generous overlap between images is the single most important capture rule. For aerial mapping the convention is roughly 70–80% forward overlap (between successive photos along a flight line) and 60–70% side overlap (between adjacent lines).
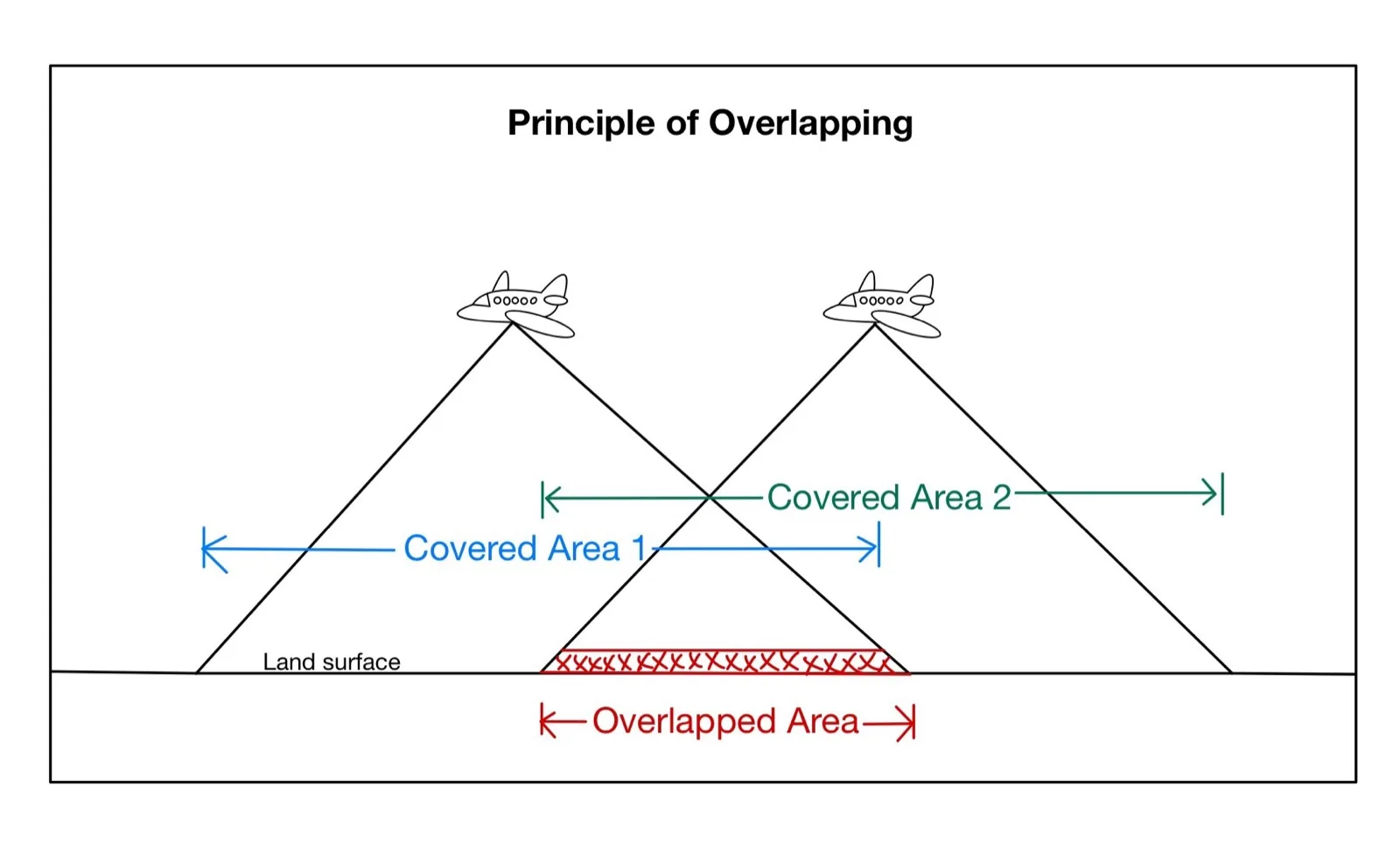
Capture for the geometry, not the gram
Blurry frames, plain textureless walls, reflective glass, water, and moving subjects all break feature matching. Even lighting, sharp focus, and lots of overlapping detail matter far more than an expensive camera. A consistent, methodical capture beats a fancier sensor every time.
Ground Control & Scale
From photos alone, SfM recovers the shape of a scene but not its true scale, position, or orientation in the real world. To anchor the model you add ground control points (GCPs) — targets on the ground whose coordinates you measure with GNSS or a total station — or you use a drone with an accurate RTK/PPK position for each photo.
With control in place, every measurement you pull from the model — a distance, an area, a volume — is in real-world units and correctly georeferenced. Without it, you have a nicely shaped model floating at an arbitrary size.
What You Get Out
Point cloud & mesh
- Dense colored points
- Textured 3D surface
- For modeling & inspection
Orthomosaic
- Stitched, distortion-corrected map
- Uniform top-down scale
- Measure directly off the image
Elevation model
- DSM (surface) / DTM (terrain)
- Contours & volumes
- Cut/fill & drainage

Strengths & Limits
Strengths: low equipment cost (any decent camera or drone), true photorealistic color and texture, and excellent results on well-lit, well-textured surfaces. It is the most accessible way to produce a 3D model.
Limits: it needs good light and visible texture, struggles with water, glass, and featureless surfaces, cannot see through vegetation the way multi-return LiDAR can, and is only as accurate as its capture geometry and ground control. For the full side-by-side, see LiDAR vs Photogrammetry.
A newer cousin of photogrammetry, Gaussian splatting, uses the same overlapping-photo input but represents the scene very differently — worth a look if photorealistic real-time views are the goal.